
Introduction
Since the Turning test proposed to use human-machine dialogue as an important way to measure machine intelligence, dialogue systems have become an important research direction in the field of natural language processing, receiving widespread attention from academia and industry.
With the development of recent pre-training techniques, the capabilities of dialogue systems have been significantly improved. Numerous open-source and high-performance English pre-trained dialogue models have become the backbone of dialogue research and applications.
In order to promote the development of Chinese dialogue systems, the Conversational AI (CoAI) group at Tsinghua University has long been committed to building open-source Chinese pre-trained dialogue models. From CDial-GPT1 to EVA1.02 and EVA2.03, we have been continuously striving to improve the performance of Chinese pre-trained dialogue models. However, compared to open-source English dialogue models such as Meta’s BlenderBot4, the ability of Chinese dialogue models is still unsatisfactory. Therefore, we aim to further break through the boundaries of open-source Chinese dialogue models.
This blog will introduce our progress in developing Chinese pre-trained dialogue model, OPD (Open-Domain Pre-trained Dialogue Model), which has the following advantages:
- Large Scale: OPD has 6.3B parameters, which is the largest Chinese open-domain pre-trained dialogue model.
- High Performance: We comprehensively evaluate the performance of OPD through both automatic and human evaluation. The evaluation results show that OPD balances excellent conversational skills and knowledge abilities. As a result, OPD can have an in-depth multi-turn conversation with users, performing significantly better than EVA2.0 3, PLATO 5 and PANGU-BOT 6 and being more favored by users.
- Open-Source: We open-source a series of Chinese dialogue system-related resources, including
- Chinese Open-Domain Dialogue Generation Model: OPD
- Chinese Dialogue Evaluation Model: Informativeness、Relevance、Consistency、Safety

Performance
Automatic Evaluation
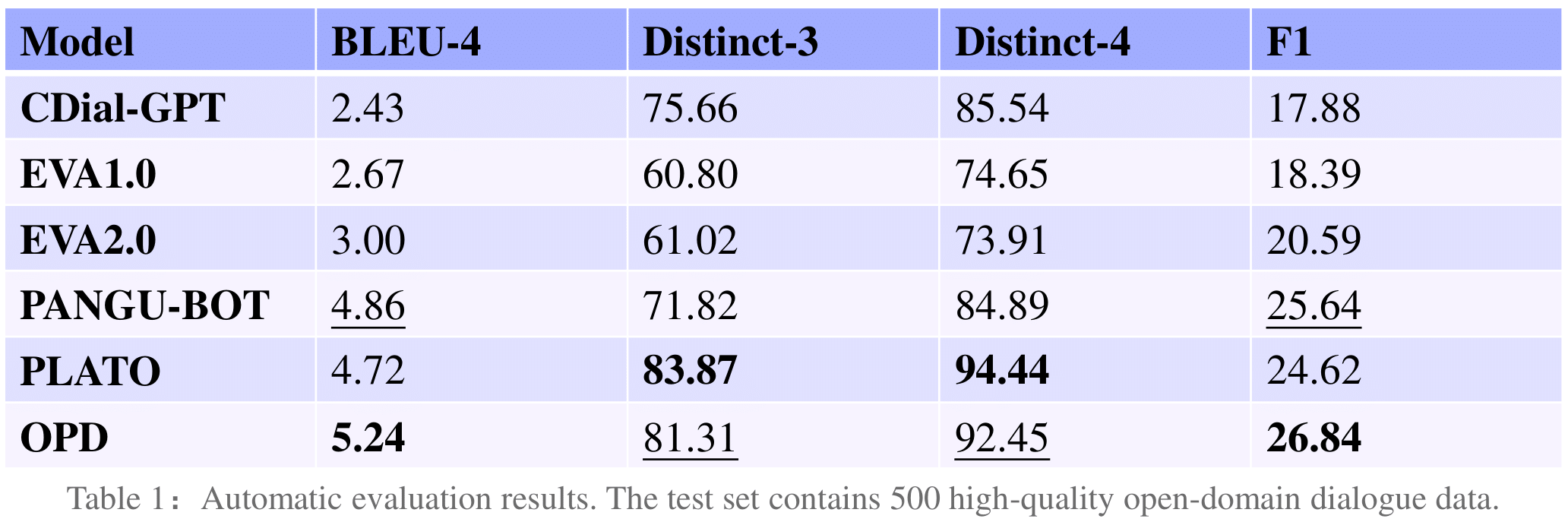
We construct a high-quality test set containing 500 open-domain dialogue data and conduct automatic evaluation on it. OPD achieves the best performance on BLEU-4 and F1 among existing Chinese dialogue models, and also comparable performance to PLATO on Distinct-3/4.
Observational Human Evaluation
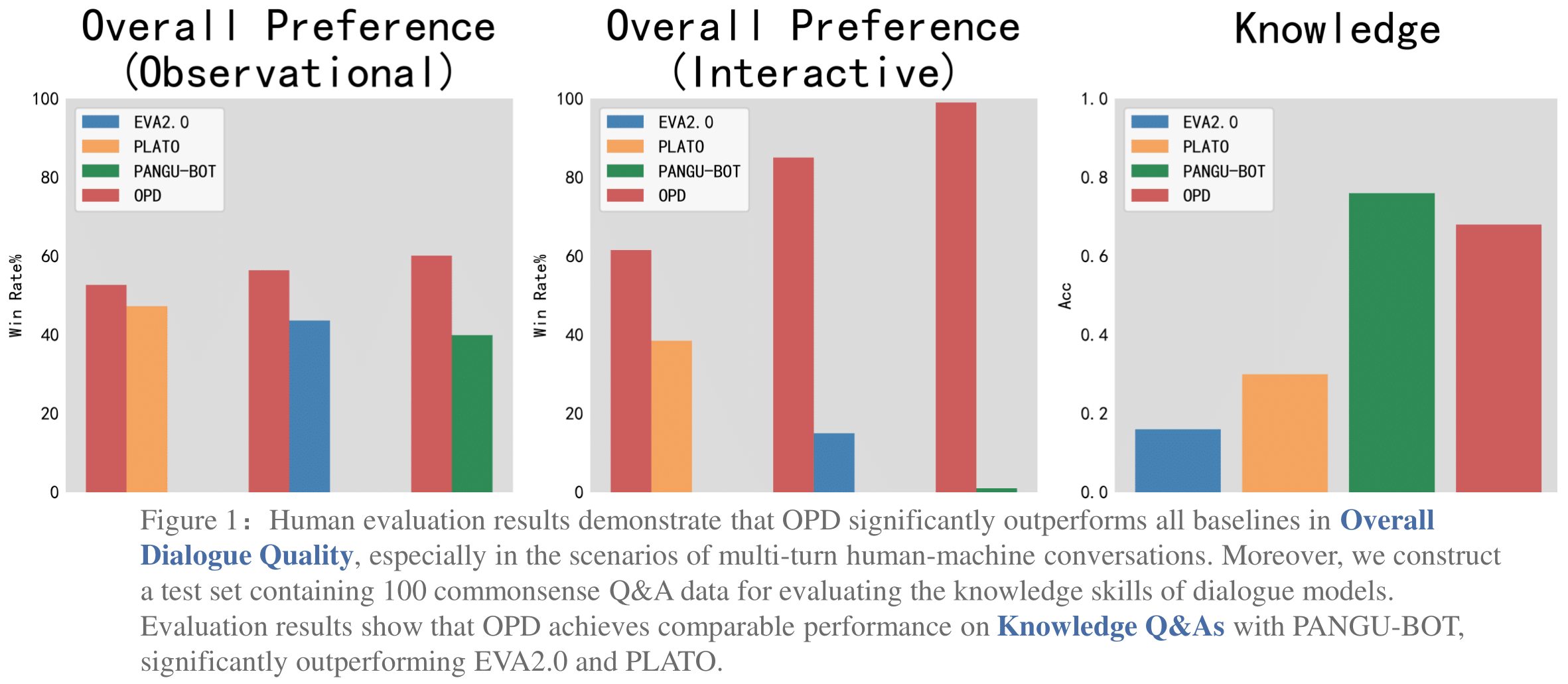
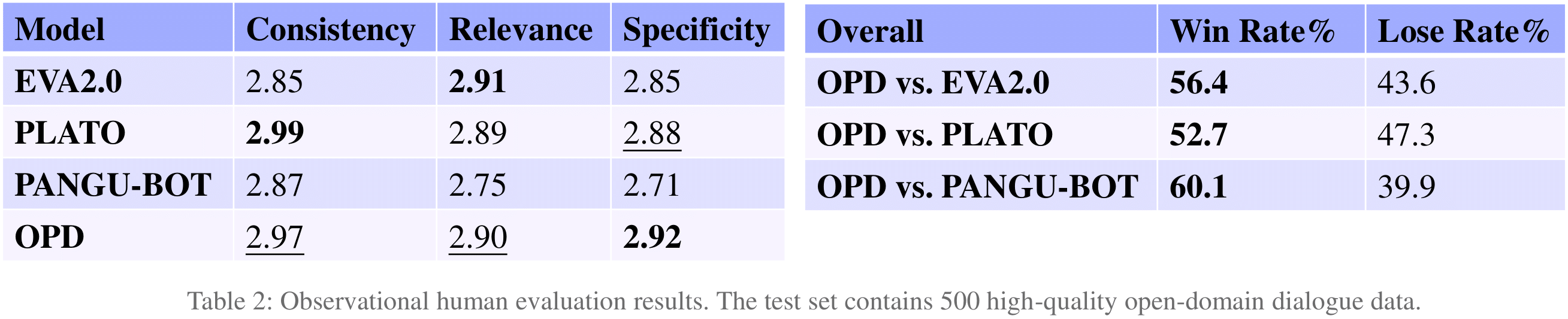
We further conduct static human evaluation on an evaluation set containing 500 dialog contexts and obtain 2,000 responses from the four model. For each response, three annotators are hired to give a score in terms of consistency, relevance, and specificity with a 1-3 Likert scale. We can see that OPD outperforms all the baseline models in terms of specificity, and also achieves similar performance to the best baseline model in terms of consistency and relevance.
We further conduct pair-wise static human evaluation. For each pair of responses (one from OPD and the other from a baseline), one annotator is hired to give a preference (win or lose) in terms of overall quality. OPD outperforms all baseline models in the pair-wise human evaluation.
Interactive Human Evaluations
We also conduct interactive human evaluation to simulate the real scenarios of human-bot conversations. Each annotator talks about the same topic with four models (the first utterances of users are the same). We require each conversation to last at least 16 turns (8 utterances from users and 8 from models). After the conversations, the annotators are asked to score the performance of each model in terms of consistency, relevance and specificity with a 1-5 Likert scale. Furthermore, they give a pair-wise preference (win or lose) based on the overall quality. The results indicate that OPD significantly outperforms all baseline models in specificity and overall quality, and performs comparably to the best baseline model in consistency and relevance.

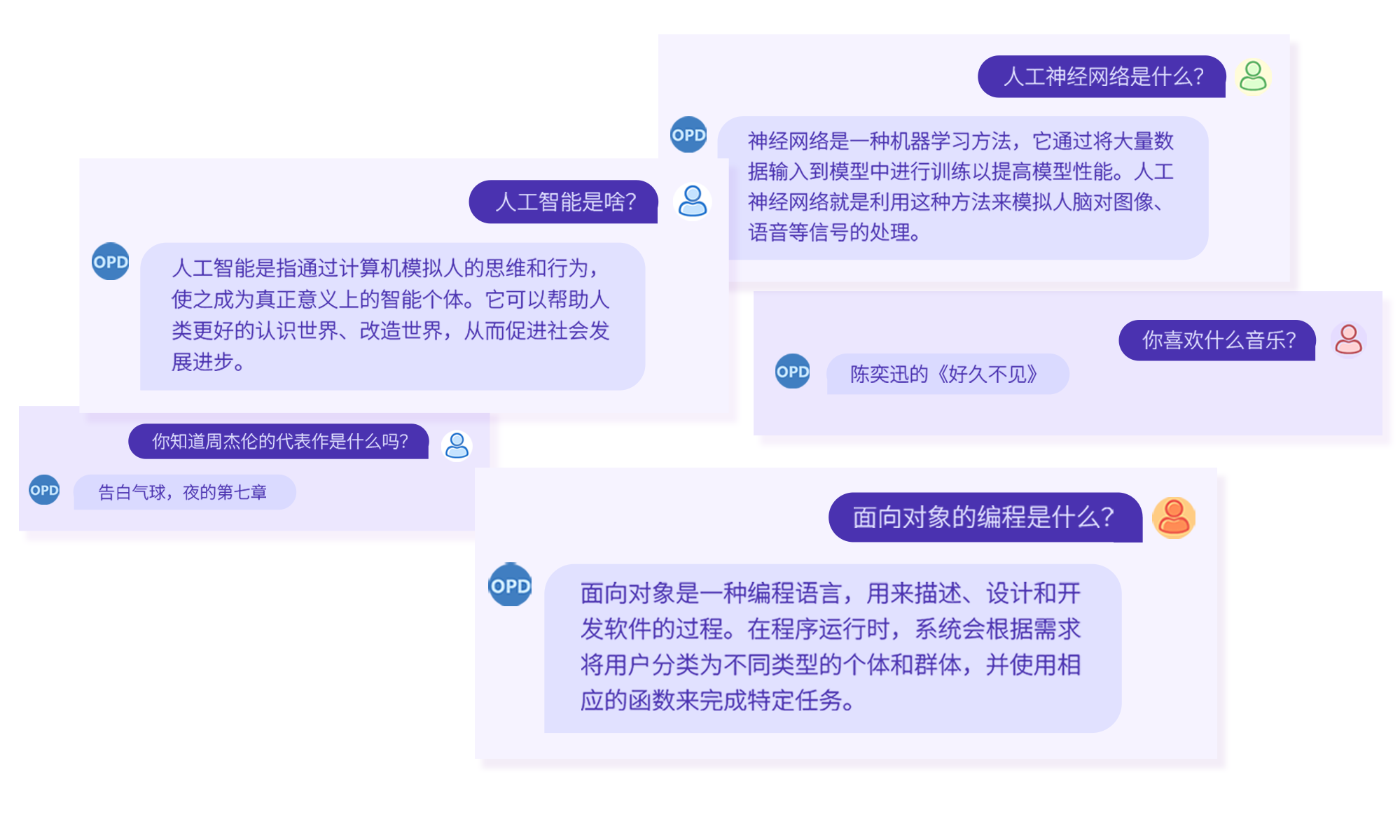
Cases
Approach
Pre-training Data
The pre-training data used in OPD comes from publicly crawlable and accessible data sources. We find in our experiments3that, compared to general pre-trained language models, pre-trained dialogue models are more sensitive to the quality of data. Therefore, we design a strict and comprehensive data cleaning process, ultimately selecting 60GB of high-quality dialogue data for OPD’s pre-training, with a data retention of about 10% before and after cleaning. The cleaning process is as follows.
First, we use a rule-based framework to preprocess data from different sources, including Weibo, Zhihu, Douban, etc. This includes not only common data normalization methods but also special rules tailored to each specific source. Then, we train three model-based response evaluation models to automatically evaluate the relevance, specificity, and interest of responses.
The final pre-training data is as follows:
Weibo[50.0%] In our preliminary experiments, we observe that the Weibo repost data is generally of low quality. Thus we remove all of Weibo repost data. For Weibo comment data, we have found a large amount of meaningless data, such as lottery entries and vote requests. Therefore, for the same context, if it corresponds to more than 100 different targets, we will delete it.
Douban[28.7%] We filter the Douban data based on group categories, discarding categories such as rental housing, which allowed us to delete a large number of advertisements.
Story[7.7%] The story data is extracted from the original novel text using regular expressions, resulting in dialogues that are rich in semantics and have a high level of complexity.
Zhihu[6.3%] The Zhihu data consists of only question-answer pairs, so all of them are single-turn data. We only deleted exceptionally long responses.
Subtitle[4.3%] The subtitle data is obtained by crawling from public subtitle websites, and punctuation marks have been added using rules. Additionally, misspelled words have been corrected.
Tieba[2.0%] For Tieba data, we choose not to concatenate the posts based on floor number because we found poor data correlation through sampling observation. Therefore, we only used the method of concatenating nested replies, resulting in shorter data turns.
Zhidao[0.7%] Zhidao data consists entirely of question-answer pairs, and the format is relatively standardized, so no special cleaning is required.

Fine-tuning Data
We collected many public Chinese dialogue datasets, including NaturalConv, DuLeMon, DuSinc, etc. After simple processing, we mixed them for fine-tuning.
Architecture
OPD adopts the UniLM7 architecture with a total of 6.3 billion parameters and uses the language modeling task as the pre-training objective. In order to ensure OPD’s multi-turn dialogue ability, we set the maximum length to 512. We introduce soft prompts8 (using a prompt length of 64 tokens) in OPD to facilitate parameter-efficient fine-tuning on downstream tasks.
Training details
During the pre-training stage, we set the learning rate as 0.01, the warmup steps as 2K, and use the Noam Scheduler to dynamically adjust the learning rate. The model sees 1.05M tokens in a forward pass, and is trained on 64 NVIDIA V100 32G GPUs for about 30 days.
During the fine-tuning stage, we set the learning rate as 1e-5, the warmup steps as 100, the batch size to be 300, the maximum epochs to be 10, and use the Linear Scheduler to dynamically adjust the learning rate.
Acknowledgements
We would like to thank Huawei and OPPO for providing the computing resources.
Citation
@misc{opd2023,
title = {OPD: A Chinese Open-Domain Dialogue Pre-trained Model},
url = {http://coai.cs.tsinghua.edu.cn/static/opd/posts/opd_blog/},
author = {Jiaxin Wen and Yi Song and Pei Ke and Minlie Huang},
month = {May},
year = {2023}
}
Wang Y, Ke P, Zheng Y, et al. A large-scale chinese short-text conversation dataset[C]//CCF International Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2020: 91-103. ↩︎
Zhou H, Ke P, Zhang Z, et al. Eva: An open-domain chinese dialogue system with large-scale generative pre-training[J]. arXiv preprint arXiv:2108.01547, 2021. ↩︎
Gu Y, Wen J, Sun H, et al. Eva2. 0: Investigating open-domain chinese dialogue systems with large-scale pre-training[J]. arXiv preprint arXiv:2203.09313, 2022. ↩︎ ↩︎ ↩︎
Shuster K, Xu J, Komeili M, et al. BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage[J]. arXiv preprint arXiv:2208.03188, 2022. ↩︎
Bao S, He H, Wang F, et al. PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning[C]//Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021: 2513-2525. ↩︎
Mi F, Li Y, Zeng Y, et al. PANGUBOT: Efficient Generative Dialogue Pre-training from Pre-trained Language Model[J]. arXiv preprint arXiv:2203.17090, 2022. ↩︎
Dong L, Yang N, Wang W, et al. Unified language model pre-training for natural language understanding and generation[J]. Advances in Neural Information Processing Systems, 2019, 32. ↩︎
Lester B, Al-Rfou R, Constant N. The Power of Scale for Parameter-Efficient Prompt Tuning[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 3045-3059. ↩︎