
Introduction
自从二十世纪五十年代著名的图灵测试提出将人机对话能力作为衡量机器智能的重要指标后,对话系统便逐渐成为自然语言处理领域的重要研究方向,受到学术界和工业界的广泛关注。随着近期预训练模型的发展,对话系统的能力得到了显著提升,众多开源开放、性能优异的英文对话预训练基座模型也成为了对话系统领域研究和应用的基石。
为了推动中文对话系统领域的发展,清华大学交互式人工智能课题组(CoAI)长期以来一直致力于构建开源的中文开放领域对话预训练基座模型。从CDial-GPT1到EVA1.02,再到EVA2.03,我们不断努力,持续提升中文对话基座模型的性能。然而需要承认的是,相比于英文开源对话模型(如Meta的BlenderBot45),中文开源对话模型的对话能力仍存在诸多不足。因此,我们期望进一步突破中文开源对话模型性能的边界。
本篇博客将介绍我们在中文对话预训练基座模型取得的最新阶段性进展:OPD,Open-Domain Pre-trained Dialogue Model。它具有如下优势:
- 大规模:OPD具有6.3B参数,是目前世界上参数规模最大的开源中文对话预训练模型
- 高性能:我们开展了自动评测和人工评测,以全面评估OPD的性能。评测结果显示,OPD兼顾出色的闲聊能力与知识性。得益于此,OPD的多轮交互能力尤其突出,能够与人类进行多轮、深入的对话交互,表现显著优于EVA2.03, PLATO6和PANGU-BOT7,更受人类偏爱。
- 开源开放:我们本次将开源一系列中文对话模型相关生态,推动中文对话领域发展。具体包括:
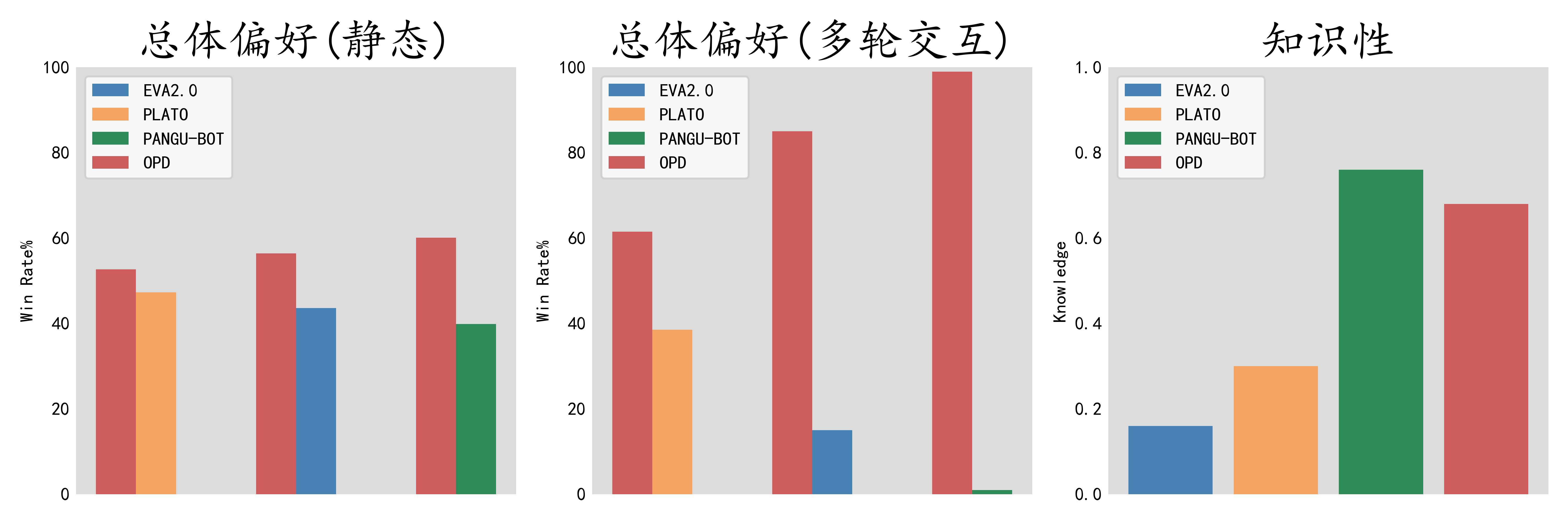
Performance
自动评测
我们在人工筛选出的500条高质量闲聊测试集上对现有的中文对话模型进行了自动评测。可以观察到,OPD不仅取得了最高的BLEU-4与F1指标,并且在多样性指标Distinct-N上也取得了最佳的表现。
| MODEL | BLEU-4 | Distinct-3 | Distinct-4 | F1 |
|---|---|---|---|---|
| CDial-GPT | 2.43 | 75.66 | 85.54 | 17.88 |
| EVA1.0 | 2.67 | 60.80 | 74.65 | 18.39 |
| EVA2.0 | 3.00 | 61.02 | 73.91 | 20.59 |
| PANGU-BOT | 4.86 | 71.82 | 84.89 | 25.64 |
| PLATO | 4.72 | 83.87 | 94.44 | 24.62 |
| OPD | 5.24 | 81.31 | 92.45 | 26.84 |
人工评测(静态)
考虑到开放域对话具有"one-to-many"的性质,我们开展了人工评测,更为全面地比较OPD与现有模型的能力。
| 模型 | 一致性 | 相关性 | 具体性 |
|---|---|---|---|
| EVA2.0 | 2.85 | 2.91 | 2.85 |
| PLATO | 2.99 | 2.89 | 2.88 |
| PANGU-BOT | 2.87 | 2.75 | 2.71 |
| OPD | 2.97 | 2.90 | 2.92 |
人工评测(多轮交互)
| 模型 | 一致性 | 相关性 | 具体性 |
|---|---|---|---|
| EVA | 1.60 | 3.40 | 2.95 |
| PLATO | 3.33 | 3.00 | 2.93 |
| PANGU-BOT | 1.95 | 2.65 | 3.00 |
| OPD | 3.00 | 3.38 | 3.30 |
交互样例
多轮
单轮
Pre-training
预训练数据集
我们使用的数据均来自公开可爬取、可访问的数据源,包含微博、豆瓣、知乎、百度贴吧、百度知道、小说对话等。
尽管大规模预训练模型本身具有一定的降噪能力,但我们在实验中发现,相比于通用语言模型,对话模型对于数据的质量更加敏感3。因此,我们设计了严格、全面的数据清洗流程,最终筛选出了70GB高质量对话数据用于OPD的预训练,数据留存比约10%。
OPD预训练数据集的详细统计信息如下:
| 数据集 | Session数量 | Token数量 | 平均轮次 | 平均回复长度 |
|---|---|---|---|---|
| PLATO | 1.2B | 75B | 2.82 | 22.0 |
| EVA2.0 | 0.29B | 22.4B | 2.80 | 20.3 |
| OPD | 0.58B | 35.4B | 2.80 | 20.4 |
模型架构
本篇博客仅对OPD模型做简要介绍,更多细节将在后续发布的技术报告中说明。
OPD采用UniLM架构,共包含6.3B参数,使用语言模型任务训练。为保证OPD的多轮对话能力,我们将模型最大截断长度设为512。还值得说明的是,OPD在预训练阶段引入了soft prompt89,以促进下游参数高效的微调。
训练资源
我们在8台V100(32G * 8)服务器上进行了为期一个月的训练。
Future Work
OPD目前仍处于“初生”状态,我们欢迎广大用户和研究人员加入OPD的社区,共同推进中文对话的发展。CoAI小组也将继续扎根中文对话领域,持续优化OPD。目前,我们主要关注的研究方向有:
- 从人类反馈中学习1011:与人类交互是对话模型最自然的应用方式,我们也在交互实验中发现了当前版本OPD存在的一些缺陷。在部署OPD后,我们将根据human-bot的交互反馈,持续改进OPD的性能,并定期发布版本迭代,与中文对话社区分享我们最新的成果。
- OPD的持续微调:我们将通过持续微调的方式,赋予OPD新的下游技能(例如:情感安抚12、知识检索13),进一步提升OPD的表现。
Contributions
Preparation
模型架构设计与实现: 温佳鑫
预实验(收敛速度、稳定性): 温佳鑫
预训练数据集构建: 宋溢
技术指导: 柯沛,顾煜贤
Model Training
大规模预训练: 温佳鑫
Post Training
模型评测(自动): 温佳鑫,万大振,宋溢
模型评测(人工): 宋溢,魏文,温佳鑫
模型服务部署(API,demo): 宋溢,彭立彪,杨家铭
对话评价模型: 宋溢,邓嘉文,郑楚杰
博客写作: 温佳鑫,柯沛
Full Project Cycle
学生负责人: 温佳鑫
项目总负责: 黄民烈
Wang Y, Ke P, Zheng Y, et al. A large-scale chinese short-text conversation dataset[C]//CCF International Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2020: 91-103. ↩︎
Zhou H, Ke P, Zhang Z, et al. Eva: An open-domain chinese dialogue system with large-scale generative pre-training[J]. arXiv preprint arXiv:2108.01547, 2021. ↩︎
Gu Y, Wen J, Sun H, et al. Eva2. 0: Investigating open-domain chinese dialogue systems with large-scale pre-training[J]. arXiv preprint arXiv:2203.09313, 2022. ↩︎ ↩︎ ↩︎
Roller S, Dinan E, Goyal N, et al. Recipes for building an open-domain chatbot[J]. arXiv preprint arXiv:2004.13637, 2020. ↩︎
Shuster K, Xu J, Komeili M, et al. BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage[J]. arXiv preprint arXiv:2208.03188, 2022. ↩︎
Bao S, He H, Wang F, et al. Plato-2: Towards building an open-domain chatbot via curriculum learning[J]. arXiv preprint arXiv:2006.16779, 2020. ↩︎
Mi F, Li Y, Zeng Y, et al. PANGUBOT: Efficient Generative Dialogue Pre-training from Pre-trained Language Model[J]. arXiv preprint arXiv:2203.17090, 2022. ↩︎
Gu Y, Han X, Liu Z, et al. Ppt: Pre-trained prompt tuning for few-shot learning[J]. arXiv preprint arXiv:2109.04332, 2021. ↩︎
Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning[J]. arXiv preprint arXiv:2104.08691, 2021. ↩︎
Ju D, Xu J, Boureau Y L, et al. Learning from data in the mixed adversarial non-adversarial case: Finding the helpers and ignoring the trolls[J]. arXiv preprint arXiv:2208.03295, 2022. ↩︎
Bai Y, Jones A, Ndousse K, et al. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback[J]. arXiv preprint arXiv:2204.05862, 2022. ↩︎
Liu S, Zheng C, Demasi O, et al. Towards emotional support dialog systems[J]. arXiv preprint arXiv:2106.01144, 2021. ↩︎
Thoppilan R, De Freitas D, Hall J, et al. Lamda: Language models for dialog applications[J]. arXiv preprint arXiv:2201.08239, 2022. ↩︎