-

-
 大规模中文对话数据集LCCC与中文对话预训练模型CDial-GPT
大规模中文对话数据集LCCC与中文对话预训练模型CDial-GPTLCCC是一个经过严格清洗的大规模中文对话数据集,包含base和large两个版本,分别包含680万和1200万多轮对话。LCCC来源于微博对话数据和开源对话数据集,经过一个两阶段的清洗过程,从9000万原始对话数据中筛选得到。具体而言,第一阶段使用一系列规则初步过滤掉不适当内容,第二阶段使用在人工标注数据上训练的分类器来进一步过滤。CDial-GPT是一个大规模中文预训练对话模型,采用GPT结构,先后在中国小说数据集和LCCC上预训练,该模型可供研究者直接用于对话生成。
查看详情 -
 KdConv:多领域知识驱动的中文多轮对话数据集
KdConv:多领域知识驱动的中文多轮对话数据集KdConv是一个中文的多领域的知识驱动的对话数据集。相比于之前的知识驱动的对话数据集,KdConv有三大特点:标注信息精细、知识交互全面、领域覆盖多样。它使用知识图谱为多轮对话中的每一句发言所使用的知识进行标注,这为知识驱动的对话建模提供了更细致的监督信号。它还包含了来自三个领域(电影、音乐和旅游)的4.5K个对话、86K个句子,这些对话包含了相关话题的深度讨论,以及多个话题之间的自然过渡。
查看详情 -
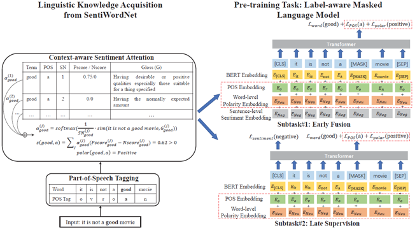 SentiLARE:用于情感分析的语言表示模型
SentiLARE:用于情感分析的语言表示模型本工作将词级别的语言学知识(包括词性和词的情感极性)引入预训练语言模型中,提出了一种适用于情感分析任务的语言表示模型SentiLARE。该模型主要包含两个模块:1) 知识获取:通过上下文感知的情感注意力机制从SentiWordNet上获取词的情感极性;2) 知识融合:以标签感知的掩码语言模型作为预训练任务来构建知识增强的预训练语言模型。实验表明SentiLARE在各类情感分析任务上均能取得当前最佳性能。
查看详情 -
 CrossWOZ:一个大规模跨领域中文任务导向对话数据集
CrossWOZ:一个大规模跨领域中文任务导向对话数据集为了推动多领域(特别是跨领域)任务导向对话的研究和填补中文任务导向对话数据的空白,我们提出了CrossWOZ,第一个大规模跨领域中文任务导向对话数据集。数据集包含6K个对话,102K个句子,涉及5个领域(景点、酒店、餐馆、地铁、出租)。平均每个对话涉及3.2个领域,远超之前的多领域对话数据集。相比之前的多领域对话数据集,我们精心设计的用户目标使对话中领域之间的依赖性更强,领域切换更自然。数据集标注信息全面,提供了对话双方的对话意图和双方的对话状态,可以用于任务导向对话系统中各个任务的研究。
查看详情 -
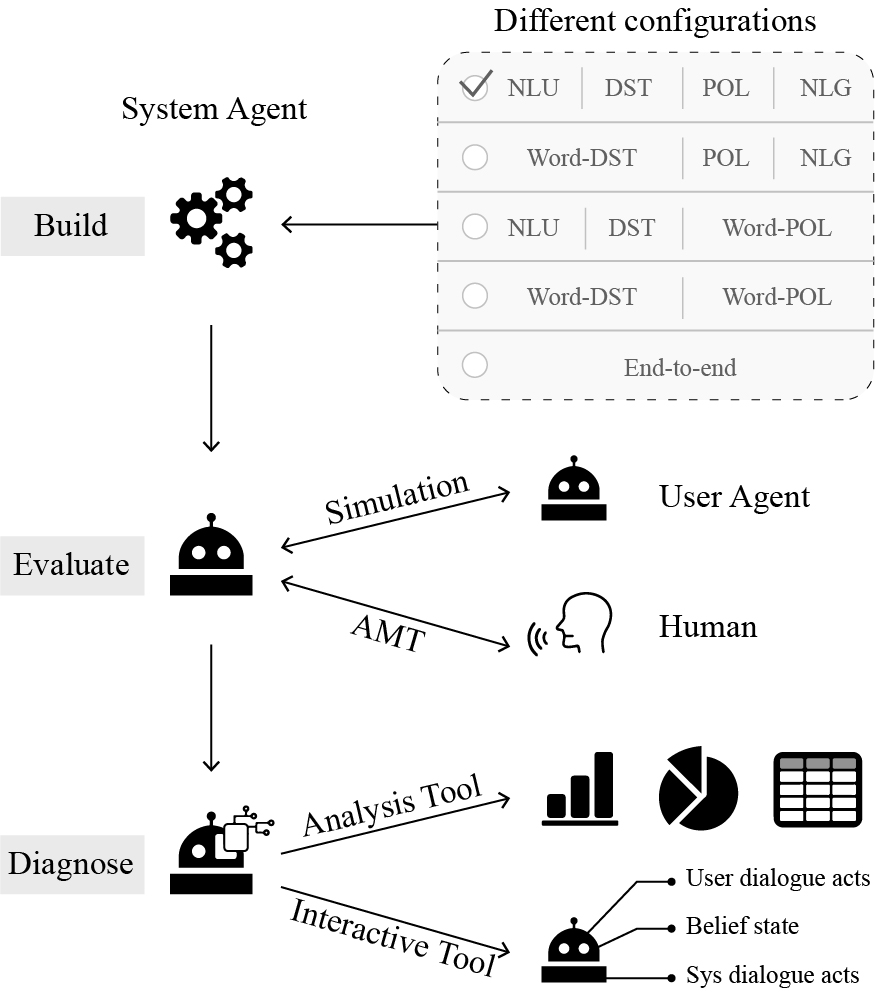 全栈式任务域对话系统平台ConvLab/ConvLab-2
全栈式任务域对话系统平台ConvLab/ConvLab-2ConvLab及ConvLab-2是由清华大学交互智能(CoAI)小组与微软研究院合作开发的任务导向对话平台。平台支持研究人员用最新的模型搭建对话系统,结合用户模拟器或真人进行端到端评估,以及使用分析工具和交互工具诊断系统的缺陷。ConvLab-2平台支持多种流水线式和端到端式的对话系统,支持的模型覆盖了各个模块,用户也可以便捷的加入自己的模型。分析工具可用于从对话中提取丰富的统计信息,总结常见的错误。交互工具可将对话系统部署到服务器,与人通过网页交互,便于诊断对话系统以及收集人机对话数据。
查看详情